





If you're building a serverless application, or just interested in how the serverless world works, one way or another you're going to end up asking yourself how to handle data. You might find something about NoSQL and end up looking for better or different ways to improve your serverless architecture. Well, the single table design is one way.
The single table design is used in NoSQL databases, and it has become more popular in recent years especially using it with AWS DynamoDB. NoSQL databases can be flexible, highly scalable, have extremely high performance, but they sacrifice some benefits such as the beautiful join clause and the normalization that exist on relational databases.
There are no joins and the alternatives to a join will cost extra money because they burn CPU. So how can this be solved? Using the single table design, the data is pre-joined creating item collections that help to get our data faster and efficiently. It literally turns all the data that exists in many relational tables into one.
Let’s check some of the benefits of this approach.
- Less and more efficient requests:
The main one is to decrease the number of requests made to retrieve the data. How is this achieved? Well, let’s make a comparison:
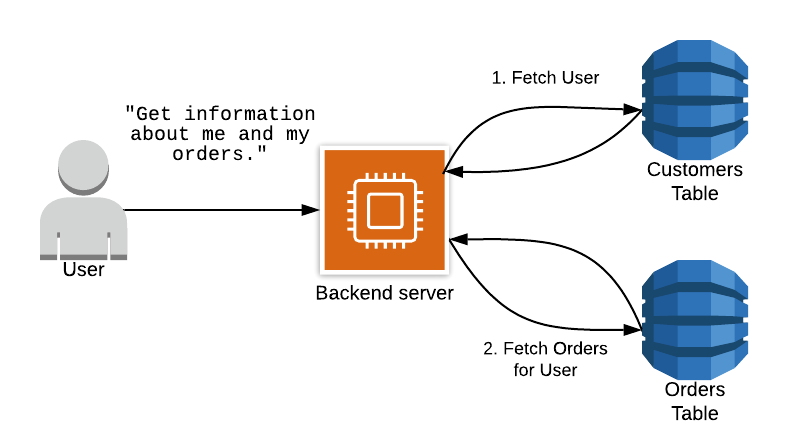
You can use a NoSQL DB with a multi-table design, exactly as you would use a relational database. This means that if you want to retrieve the information to get a simple request like getting the orders of a user you will have to make two requests: one for the customers table, and another one for the orders table, as you can see in this graphic:
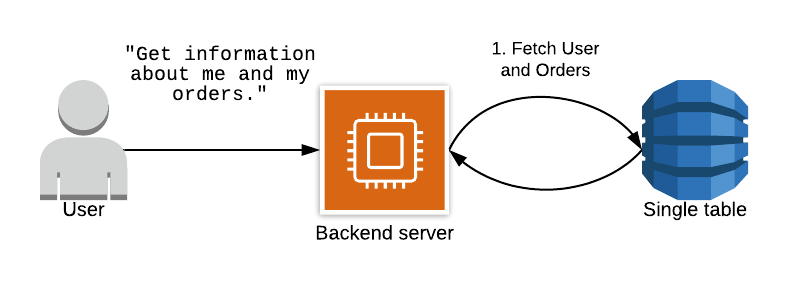
But if you use the single table design you will be pre-joining the data and there will be only a need for a single and more efficient request, as you can see in this graphic.
- Save us money:
As you probably know the RDBS services were developed specifically to reduce the costs of storage: it optimizes the way to store our data, but the CPU does suffer from difficult queries. Storage is really cheap in comparison to the processing. The trick is to avoid charging the processor with heavy loads of joins.
- Centralizing and monitoring:
When working with Dynamo all the metrics and data can be monitored for each table. So with the multi-table design, you will need to set up the monitors for all the tables created, and set alarms, and boards, and any other data that you would like to check.
And with the single table approach, you only have to take care of the health of one table.
Changing the mindset
Now that you have an idea of what the single table design is, you have to acknowledge that it can be a bit hard to change the mindset. But if you're looking for a really affordable and highly scalable design it’s worth researching a bit more about it. I can recommend Rick Houlihan's and Alex Debree's material. They both have been precursors and have amazing videos explaining this approach and how to use it.
The pet project: How to model a single table design.
To explain how and why to use the single table design, there is nothing better than an example. The steps below describe the recommended way to model data for NoSQL with a single table design.
1. Understand the application you're building and its use cases.
It’s crucial to understand the application to be built and define the use cases that it's going to have. For single table design it's even more important because the model is hard to update on the run and to pre-join the data and be able to retrieve it according to the needs, it's important to previously detect the data to be used.
So to do that, a good exercise is to start asking questions. Start digging with the customer or with whoever is going to give the information for the app and ask questions until it's completely understood how the data should be handled. For this example the following questions and answers were collected.
- What kind of application is being built?
- Answer: An OLTP application receives leads of potential clients that would like to buy cars and shows the information to the administrators so that they can handle the lead according to their needs.
- Which data should be available for the administrator users?
- The objective is to start defining all the information the app will need to present and this will be turned into the access patterns later.
- Answer:
- The clients
- All the quotations.
- Which products the client has requested
- The products by make, category, and quotation status.
- What reports do you need to receive?
- Quotations by date
- Quotations by product, category, make and date
- Quotations by status, product and date
- Quotations by source and date
- How do the data relate to each other?
- Here the best approach could be to create a relational data model, to have visual representation:
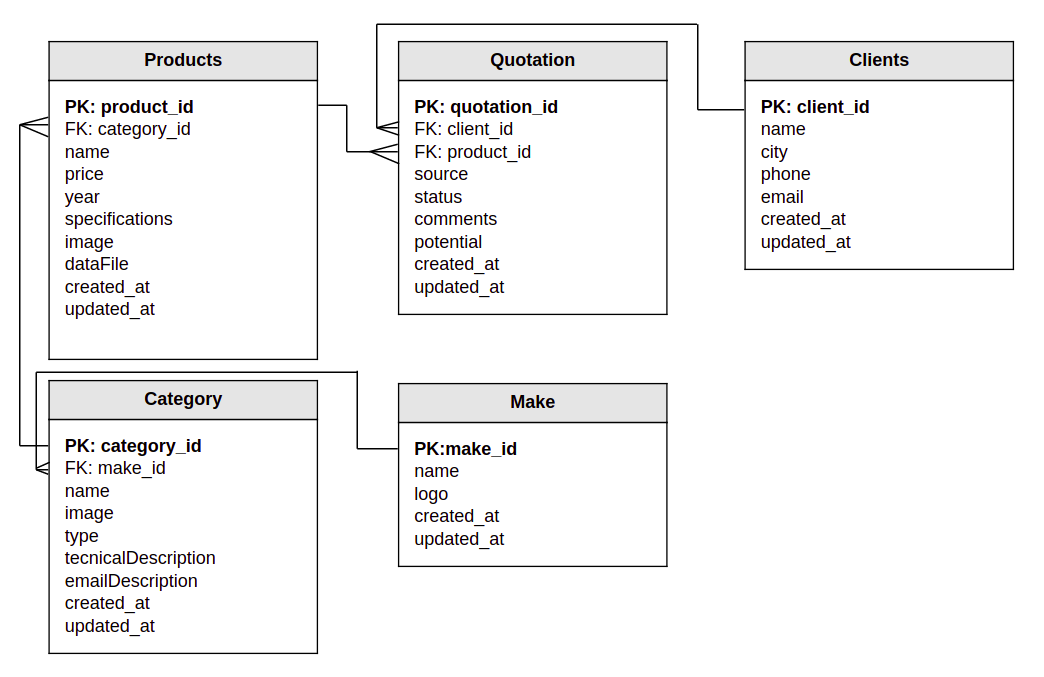
2. Access patterns
All the answers retrieved from the client about how the app is going to work and which data is going to be displayed are useful for creating the access patterns.
The access patterns define how the single table is going to handle the exact information. The way to define the access patterns of the data is to write them down. As shown in the following example:
- Get all products
- Get product by id
- Get products by category
- Get products by make
- Get products by quotation status
- Get category by id
- Get category by make
- Get all categories
- Get make by id
- Get all makes
- Get all clients
- Get client quotations by source
- Get quotations and client info by client
- Get quotations by date
- Get quotations by status
- Get quotations by make
- Get quotations by product
- Get quotations by category
- Get quotations by status and date
- Get quotations by status, date, and product
- Get quotations by status, date, and category
As you can see the list above gives a clear idea of how the data is going to be modeled in the design, and which data should be pre-joined. For example, the access pattern “Get quotations by client” means that the table quotation and client should be pre-joined in order to get the data in one query.
Also, it shows all the tables to take into account in the model. This would be easy to recognize in relational databases, but in access patterns, they are represented with “Get all the products”.
So this list must be well defined because it's extremely important to cover all the use cases for the application.
3. Data modeling
Now that the access patterns are well defined, the next step is to model the data into the single table design.
It's recommended to use any modeling tool, for example, NoSQL WorkBench is an AWS tool that you can get for free, and you can even connect to your database and start making queries for testing purposes.
Partition Key, Sort Key, Secondary Indexes?
To model the data, it's important to know that the single table design is formed by three important keys.
- PK: The partition key is the unique required identifier of the items in the table. It does not let you create relations with other tables. It's just there to uniquely identify the items across the table. It can be a string, number, or binary value.
|
Example of a single table only with Partition Keys
Table name: Quotations |
|
| Partition Key | name |
| PRODUCT#W183JD83JK | Mustang |
| CATEGORY#E823JD08 | Sports car |
| CLIENT#JD92KD93 | John Doe |
| MAKE#W183JD88JE | Ford |
The example above shows exactly how a single table design might look using only a partition key and an additional field ‘name’. There are several entities in the same table, but they can be queried by the partition key. So for example if you want to retrieve the product with the ID ‘PRODUCT#W183JD83JK’ you can do:
SELECT * FROM Quotations WHERE PK = 'PRODUCT#W183JD83JK'
The partition key helps us cover the ‘Get by id’ access patterns.
NOTE: The SQL statement above is just a reference. In NoSQL and DynamoDB, PartiSQL is used, but the best practice is to query using the SDK. So for example in JS the queries will look like this:
export const getProduct = async (productId: string) => {
const params = {
Key: {
PK: { S: productId },
},
TableName: TABLE_NAME,
};
return dynamo
.get(params)
.promise()
.then((result) => {
return result.Item;
});
};
Now, what about the other access patterns? For example, ‘Get all products’ or ‘Get all products by make’. Here is where the sort key comes in to help.
- SK: The sort key, this key is optional but helpful. Its function is to help sort and search through the table. So, to be able to get all the products or all the makes the sort key can contain the type of the item to be able to query them. Like this:
|
Example of a single table only with Partition Key and Sort Key
Table name: Quotations |
||
| Partition Key | Sort Key | name |
| PRODUCT#W183JD83JK | PRODUCT | Mustang |
| PRODUCT#W1444283JK | PRODUCT | A4 |
| PRODUCT#W1444283JK | PRODUCT | A5 |
| CLIENT#JD92KD93 | CLIENT | John Doe |
| MAKE#W183JD88JE | MAKE | Ford |
If you notice, the access pattern “Get all products” hasn’t been resolved yet only by the use of a sort key. Here is where the global secondary index is introduced because all the queries require a partition key, and the partition key doesn’t allow you to make any conditions, it just searches by id.
When a sort key exists, it lets you query with conditions like BEGIN WITH, EQUAL, LESS THAN, HIGHER THAN. But if the partition key is always different, it won’t work to solve the access patterns ‘Get all products’ or ‘Get all products by make’. So here is where the GSI comes in to help.
- GSI: The global secondary indexes help to project, search and order the data according to the partition key and secondary key chosen for this index. To make this clear with an example, to solve the ‘Get all products’ or ‘Get all makes’ access patterns a reverse key GSI can be created like this:
|
Example of a single table only with Partition Key and Sort Key
Table name: Quotations |
||
| Partition Key | Sort Key | name |
| PRODUCT | PRODUCT#W183JD83JK | Mustang |
| PRODUCT | PRODUCT#W1444283JK | A4 |
| PRODUCT | PRODUCT#W1444283JK | A5 |
| CLIENT | CLIENT#JD92KD93 | John Doe |
| MAKE | MAKE#W183JD88JE | Ford |
Reverse means to project the same data but using the SK as PK, and the PK as SK to be able to sort. This strategy solves the access pattern ‘Get all products’:
SELECT * FROM Quotations WHERE PK = 'PRODUCT'
This not only solves those access patterns. This will also solve ‘Get all clients’, and ‘Get all makes’ and others. To make this easier and more ‘real life’ below you can see the actual table with all the example data of the pet project:
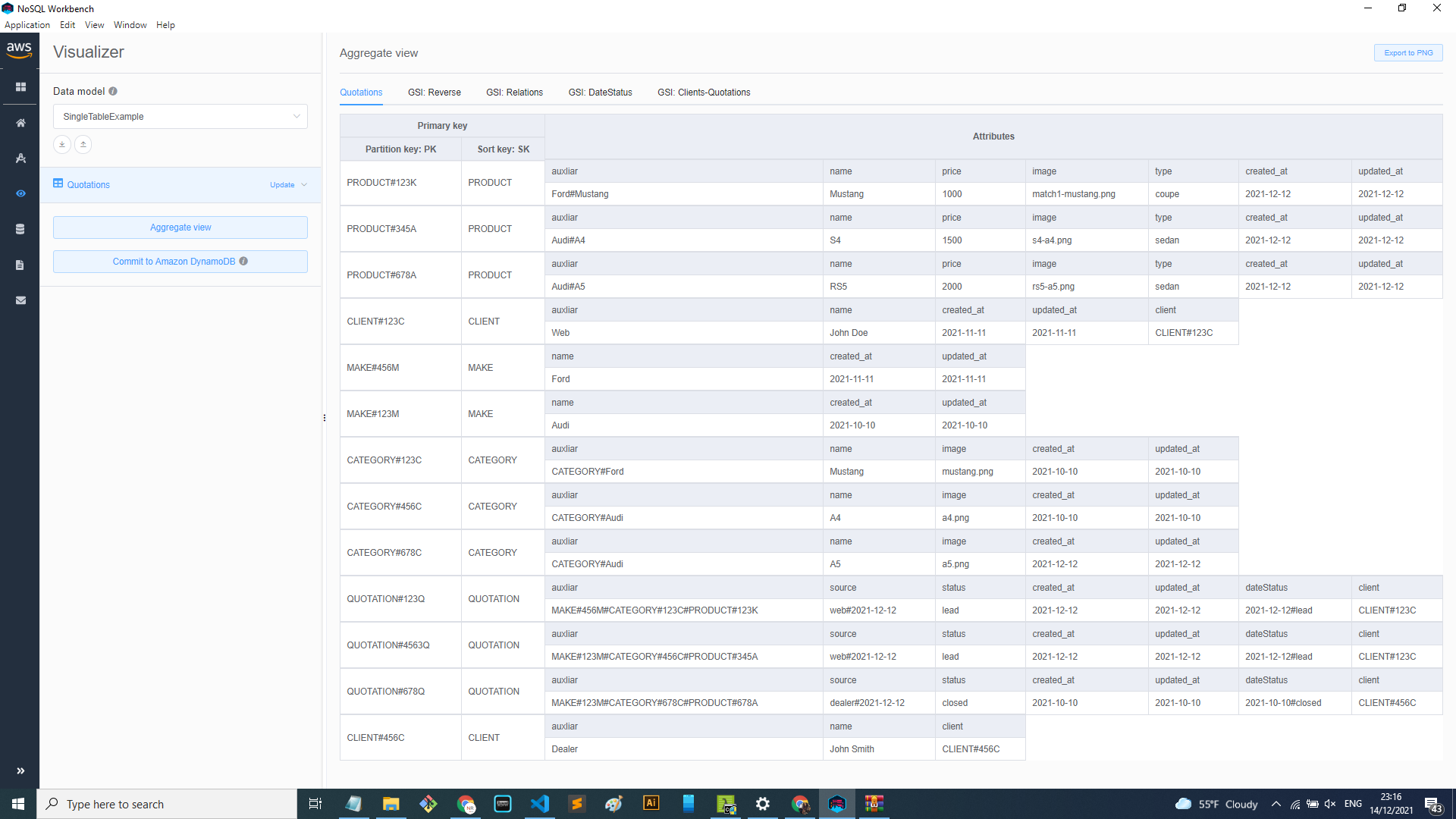
Now, applying the GSI: Reverse
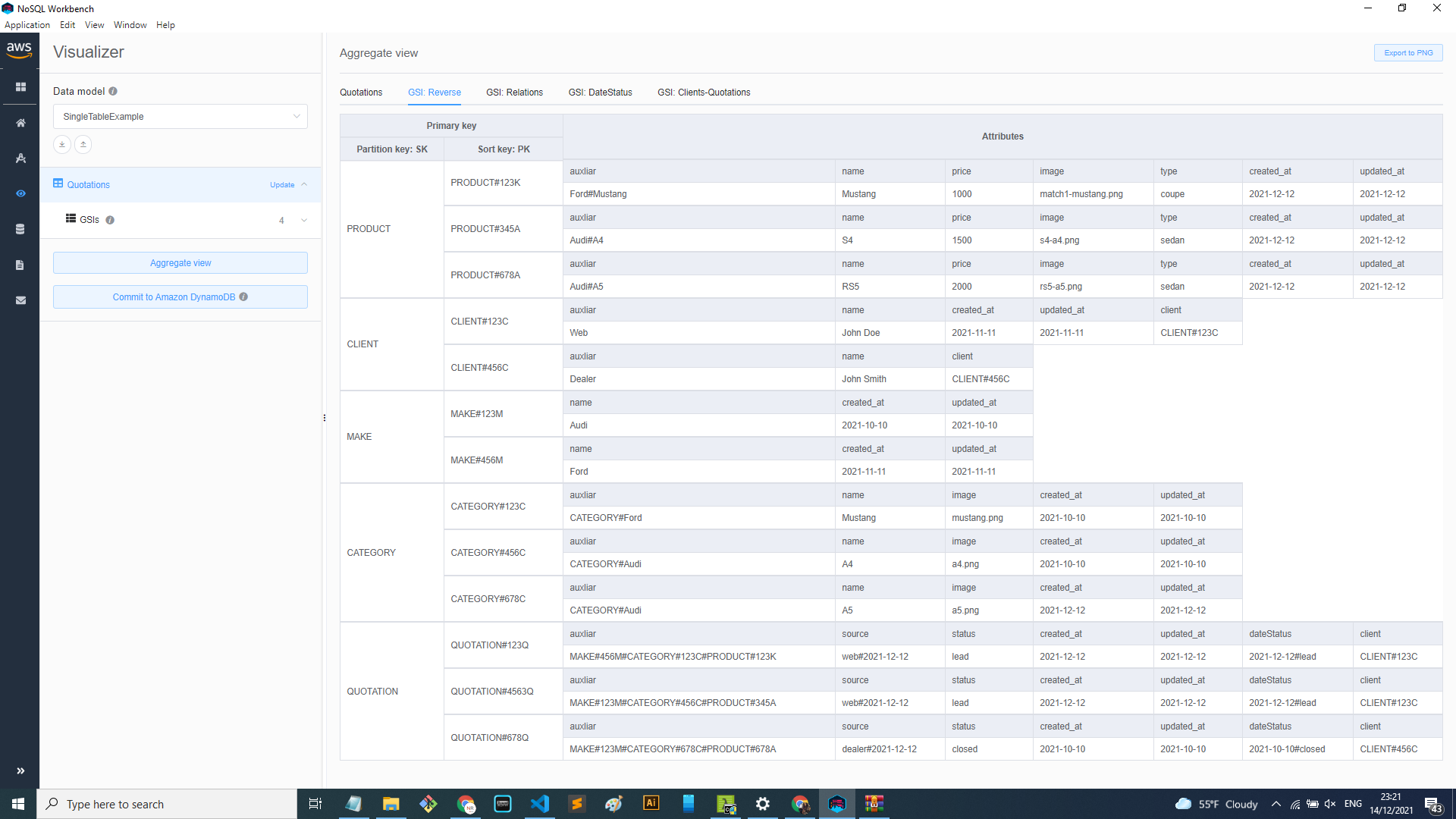
And what about all the other access patterns? To be able to solve them, more GSIs can be created and more fields that can help to query the information according to what is needed. That is why it's so important to define the access patterns first. Because it's the only way to know what strategies, GSIs, and keywords to use.
For the pet project, the following additional fields and GSIs were created:
GSI Relations: This one uses the SK as PK and “auxiliary” as SK. This makes it easy to solve the access patterns like: Get all products by make, by category, get all quotations by make, category, product.
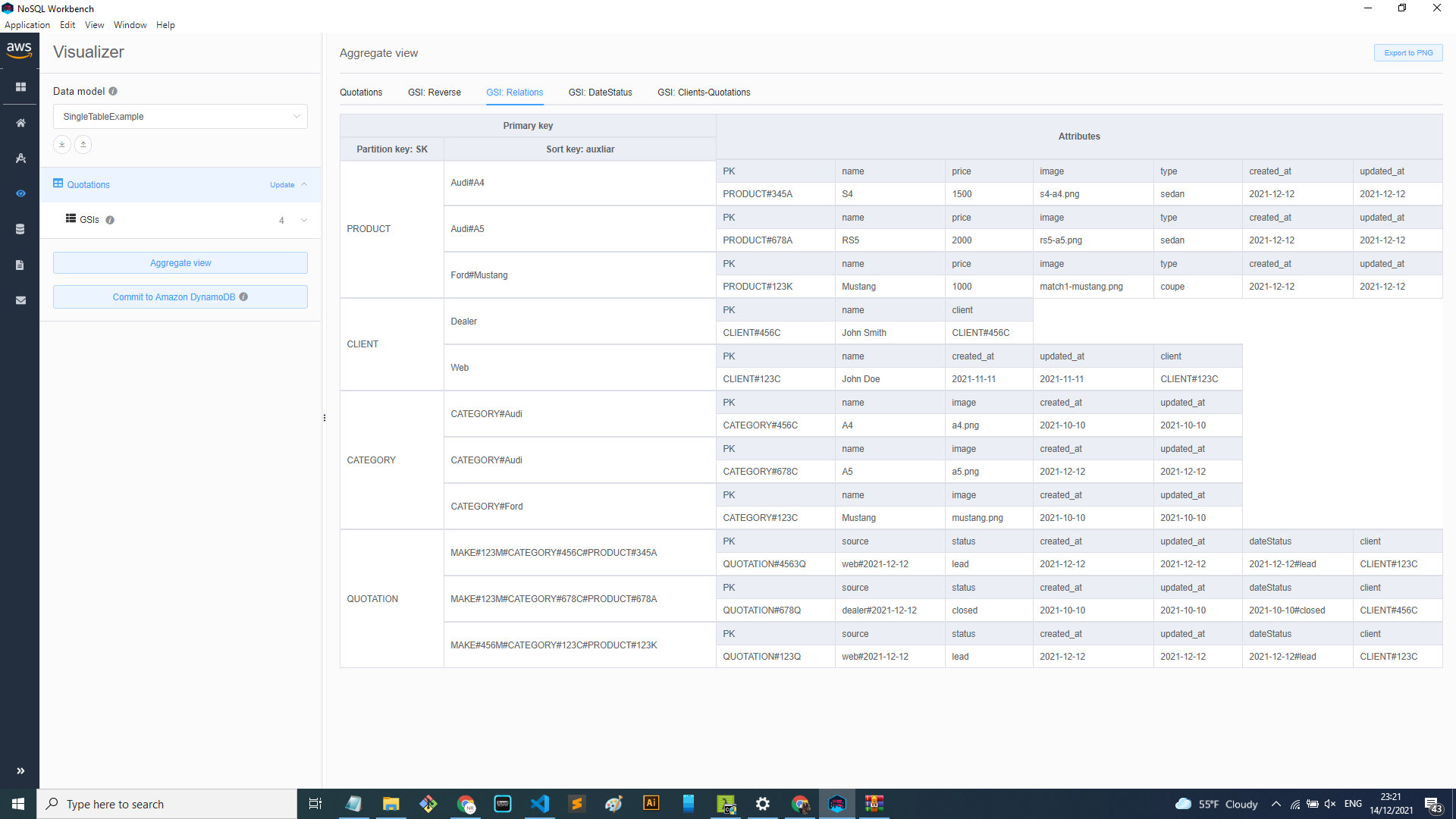
As you can see the “auxiliary” field has values like Audi#A4, or MAKE#123#CATEGORY#123#PRODUCT#123. This also has a purpose, which is to be able to query using CONTAINS or BEGINS WITH.
To have all the keys in one field makes it easy to solve the access patterns described above.
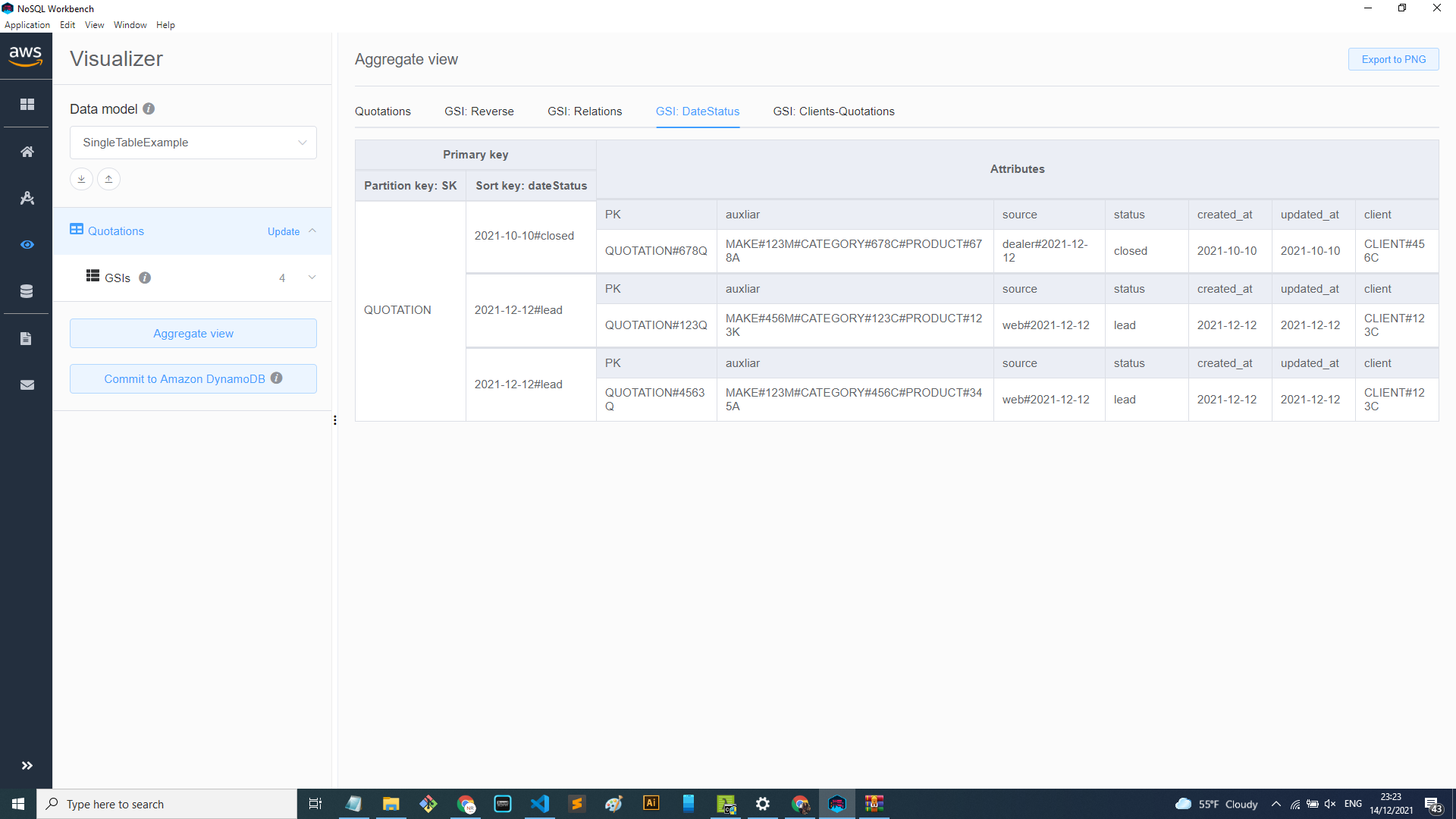
GSI DateStatus: This index helps to get the Quotations by date and status. A specific field “dateStatus” was created to join the date and status. That way is easier to query by a date range and the status of the quotations.
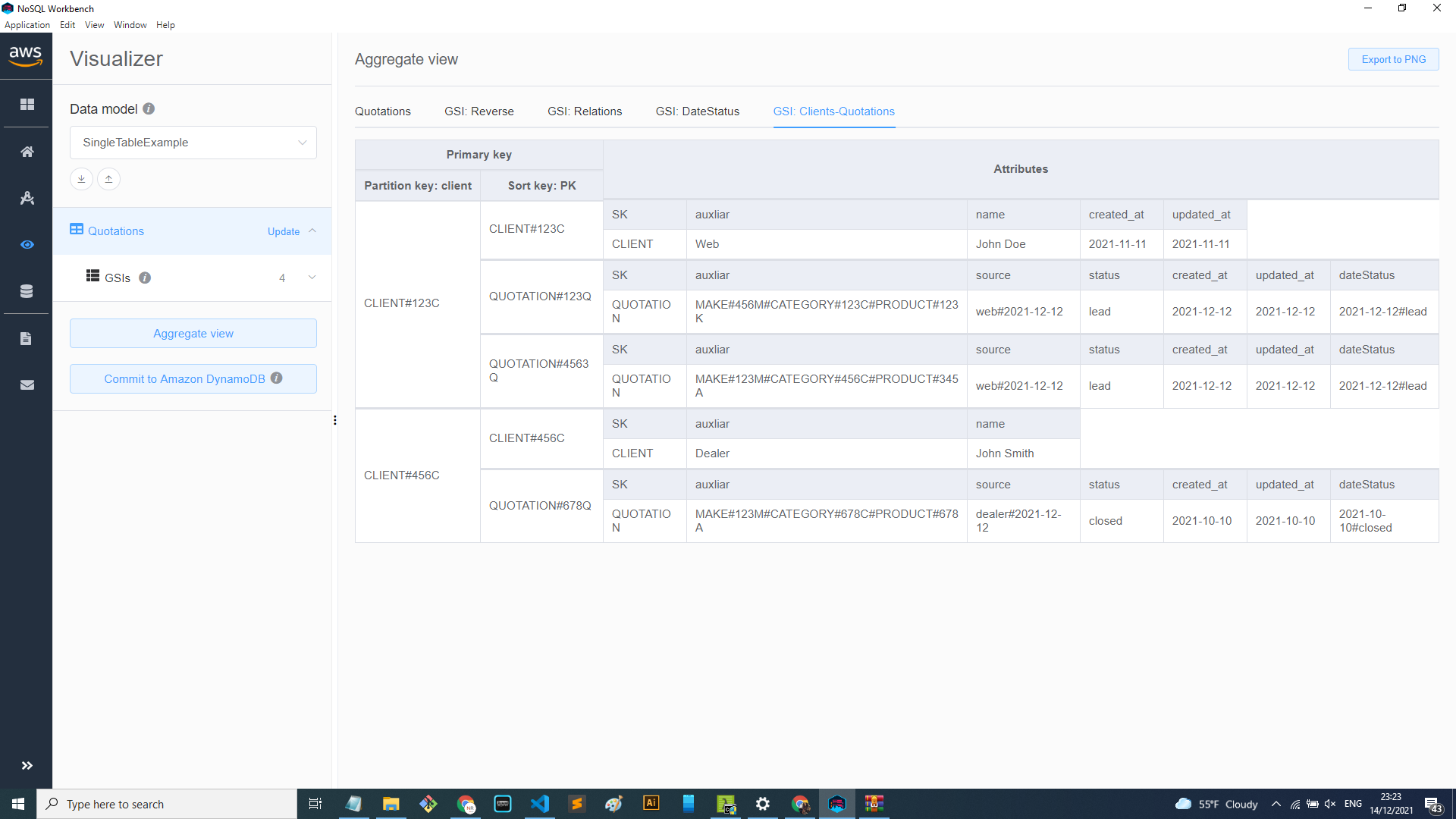
GSI Clients-Quotations: This last index serves the purpose of joining tables Clients and Quotations. Because one access pattern is ”Get all client quotations and client information”. So in order to avoid making two queries, this GSI allows you to retrieve both tables in one query as you can see in the image below.
Wrapping up
This blog post reviewed the basics of the Single table design and the reason for its existence. Also, the pet project showed a sneak peek on how to start modeling your data, following the recommended steps, and there are several strategies and approaches able to solve the different situations for the use case.
Below are some aspects to consider and the advantages and disadvantages of using this design.
Benefits:
-
Once you have the model and start testing it, the speed you get is unbelievable. Diminishing the requests and combined with Dynamo it works like a breeze.
-
In fact it's easier to maintain only one table, especially because you have many settings like permissions, IAM roles, networks, monitoring, triggers, and others. So in fact having to worry about only one table can be easier.
-
It's a good practice for OLTP (Online transaction processing) applications and is specially focused on serverless architectures. For reference OLTP applications handles small CRUD transactions at high speed, increasing the end user productivity. For example ATM, leads, e-commerce transactions, retail applications, order entry.
-
Another important aspect of using this approach is that it helps you to think better about your application before you start writing code. So this gives a better result in the final design and product itself because you consider all of the aspects in order to get the access patterns.
-
Building the table with infrastructure as code makes your database reusable and it can be easily migrated to any environment where you want to use it.
Disadvantages:
-
Probably one of the most difficult parts of using this approach is changing the mindset and the learning curve. It’s important to know that building a single table design can be difficult and you will need several iterations until you meet the objective of covering all the access patterns.
-
It's difficult to add new access patterns once the table is built and running. Another thing to notice is that once you have large amounts of data filling the database you won’t be able to access the database and normally read the table as you would do it with the multitable approach. It's going to be hard to read (almost hieroglyphics!) because all the data is going to be mixed, so you will need to perform queries or check via your GSIs in order to make the data readable.
-
You wouldn’t be able to export the database to perform analytic processes. Again, all the data is mixed and denormalized probably repeated so you might be able to get a GSI that covers the analytics you need to perform but still wouldn’t use it if that is the use case.
When to use it and when to avoid it
Use it:
As mentioned before the single table design is a good practice for OTLP applications, which means it’s made to facilitate user transactions with high speed. For example, using an ATM, facilitating CRUD operations like handling leads, e-commerce, booking tickets, or sending text messages and others. There is a huge amount of applications you can build.
OTLP uses transactions with a small amount of data but has a large number of users and should have fast response times. Which if you think about is exactly what the single table design provides.
Avoid it:
The answer should be the opposite to OLTP applications: avoid it in OLAP applications. This type of application requires complex data analysis which means complex queries and as explained before the single table design doesn’t work well with complex queries; the point is to keep it simple.
For example marketing analysis, financial reporting, management reporting: all of these basically check all the database and perform complex queries which is exactly what single table design doesn’t like to do.
Another obvious case when not to use it is when you don’t know exactly what the application is going to do. You will be developing new features according to what you might need, this is not suitable because adding new access patterns can be a challenge.
Recommended articles and workshops:
Finally here is a list of recommended readings and video workshops that help a lot to understand better the concept and how to use the single table design: