





In Part 2, we laid the theoretical groundwork and practical template for property-based testing. Now, we turn our attention to a real-world example that showcases the usage of this testing methodology. We will also explore the challenges involved in debugging when working with property-based tests. Join us as we navigate through real-world scenarios, demonstrating how property-based testing not only identifies problems but also equips us with the insights to address them effectively.
Real Example and debugging
Real Example:
Now that we have an understanding of what property tests are and the technical concepts to start writing them, let’s make a more real example using them.
Working with some legacy code, we found some JSON structures were malformed. It was complicated to fix these structures because the data was distributed in multiple databases. The problem was that the JSON structures had booleans that were sometimes treated as strings and sometimes treated as booleans, as follows:
{
text: “This is a text string”,
marks: [ { bold: true, italic: false } ]
}
{
text: “This is a text string”,
marks: [ { bold: “true”, italic: “false”} ]
}
Also, there was an issue where sometimes marks were arrays, and sometimes these were objects as follows:
{
text: 'text',
marks: { bold: true },
}
{
text: 'text',
marks: [{ bold: true }],
}
This was causing a bug when the content was rendered because the format marks like bold, italic, underline and others were not applied. In order to fix this, we decided to add a legacy conversion function to support all the cases.
To test this function with example-based tests, we would have to start writing cases like “when a node with array marks comes in, it should convert to valid format” “when a node with object marks comes in, it should convert to valid format” “when a node with array text marks comes in, it should convert to valid format” “when a node with an array of mixed text and boolean marks comes in, it should convert to valid format” And so on…
The possibilities are extensive because we have to control several cases; there can be text, booleans, arrays, and objects, so writing this by hand can be a lot of copy-pasting; also, we might miss some edge cases. So here is a perfect place to implement a property-based test. You can check one of the property tests we implemented:
describe('given any array of text or boolean marks when convertLegacyMarks is called', () => {
it('returns an object of valid marks and boolean values', async () => {
fc.assert(
fc.property(
fc.record({
text: fc.string(),
marks: fc.array(
fc.dictionary(
fc.constantFrom(
'bold',
'italic',
'strikethrough',
'code',
'underline'
),
fc.oneof(
fc.constantFrom('true', 'false'),
fc.boolean()
)
)
),
}),
(data) => {
const convertedMark = convertLegacyMarks(data)
expect(isObject(convertedMark)).toBeTruthy()
Object.values(convertedMark).map((mark) =>
expect(isBoolean(mark)).toBeTruthy()
)
Object.keys(convertedMark).map((k) =>
expect(validMarks.includes(k)).toBeTruthy()
)
}
)
)
})
})
Breaking this up as we did above we can see in this test:
arbitraries: This arbitrary is defined to create multiple inputs that cover the use cases defined above and will combine the marks with booleans, texts and also consider all the kinds of marks that we can have.
fc.record({
text: fc.string(),
marks: fc.array(
fc.dictionary(
fc.constantFrom(
'bold',
'italic',
'strikethrough',
'code',
'underline'
),
fc.oneof(
fc.constantFrom('true', 'false'),
fc.boolean()
)
)
),
})
myFunction: We receive the arbitrary in “data” and run our function
const convertedMark = convertLegacyMarks(data)
predicate: Finally, we create several assertions that cover our requirements for the conversion
expect(isObject(convertedMark)).toBeTruthy()
Object.values(convertedMark).map((mark) =>
expect(isBoolean(mark)).toBeTruthy()
)
When the test is run, fast-check generates several inputs and runs the test. If the function is not fulfilling the requirements, the test fails. Let’s see what happens after running the test with a bad implementation:
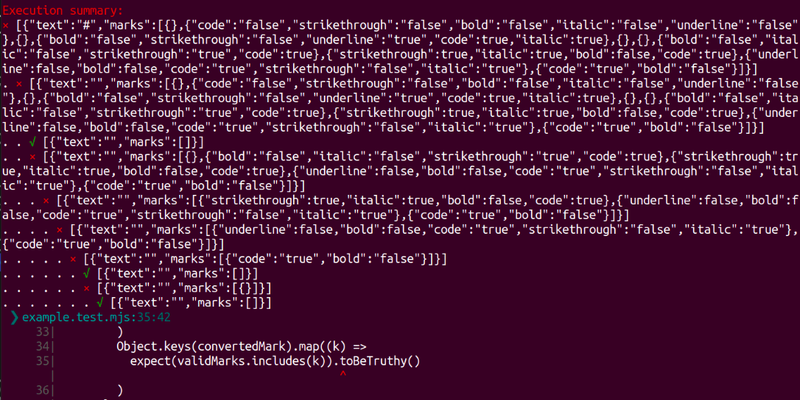
For easier debugging and to showcase how the runner generates the inputs, I added an option to the runner { verbose: 2 }; this option generates an error report with all the inputs that were tested. As you can see above, it creates all sorts of crazy inputs. You can imagine that it would take a lot of copy-pasting to test all these values.
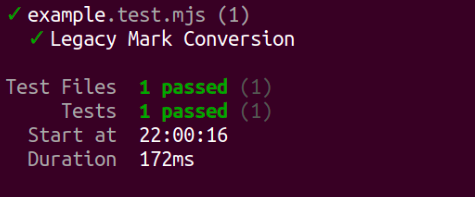
If the test passes, it will return a green light:
Detecting issues:
Usually in example-based testing, once we run a test and it fails, we know what might be failing because we wrote the case and have an instant clue of what is happening. But in property-based testing, as it generates multiple inputs, how do we know what is failing and what we should fix?
We can do this by reading the test report that fast-check delivers, which looks as follows:
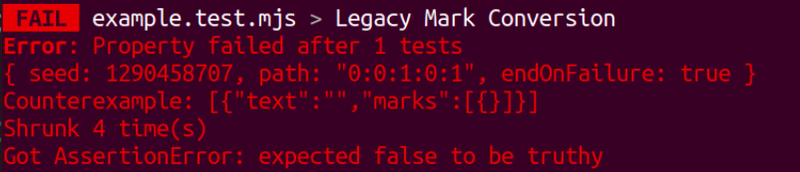
The exact value where the test failed is located in the “Counterexample”:
[ {"text":"","marks":[ {} ] } ]
Also, the reason for the failure is returned in the “Got AssertionError” line:
“expected false to be truthy”
Since our assertion is expect(isObject(convertedMark)).toBeTruthy(), we can determine that the function is not working correctly because it returns an array instead of an object.
What if we want to test the same value that failed to avoid testing everything and having the certainty that the issue is solved? A seed is provided to us:
{ seed: 1290458707, path: "0:0:1:0:1", endOnFailure: true }
This seed can be passed to the runner as follows, and it will run the predicate directly to the reported failure. As property-based testing is fully deterministic, all tests are launched with a precise seed, so you will get the same set of values every time.
test('Legacy Mark Conversion', async () => {
fc.assert(
fc.property( ..., (data) => {
const convertedMark = convertLegacyMarks(data)
...
}
),
{
verbose: 2,
seed: 1290458707,
path: '0:0:1:0:1',
endOnFailure: true,
}
)
})
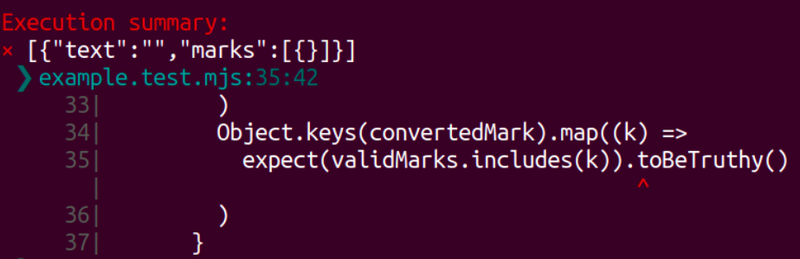
As you can see, this time, it only ran the same exact value that belongs to that seed. This gives us flexibility for debugging and finding the edge cases.
Conclusions
Does property-based testing replace unit tests?
Since both are different, as we saw in the analogy, they serve different roles and have their own pros and cons. Property-based testing is good at finding edge cases and can help catch unnoticed errors in a method. But even though fast-check or other libraries let you set specific inputs that you want to test, it doesn’t replace the example-based test characteristic of checking specific scenarios for certain purposes that can help you document and deliver a better understanding of the function.
The same happens with granularity: unit tests can help catch specific issues or logic errors in a function, but property tests use broader inputs and high-level properties that should hold true across different parts of the codebase.
While property-based tests are useful for finding unexpected issues and checking high-level properties or conditions, unit tests are essential for thoroughly testing individual code units, guiding design decisions, and providing feedback during development. Integrating both approaches, alongside complementary testing techniques such as integration and end-to-end testing, can be an effective strategy for ensuring robust software quality.
Benefits
- With arbitrary data or automatically generated values according to our specifications, we can cover a large and diverse set of inputs that can help reveal hidden bugs or edge cases that developers sometimes overlook or bypass. Usually, we try to cover most of the cases with example-based tests, but it would be really complicated and probably repetitive to copy-paste and add 100 cases for each method.
- The maintenance of the tests can become easier because we only have to take care of the property itself instead of changing all the example-based tests.
- We can avoid over-specifying tests; the developer can write example-based tests for a better understanding of the method. But if you think about it, sometimes we see tests that check for cases we don’t care about.
- Property-based testing provides broader coverage for functions' behavior and purpose by guiding us to define meaningful properties that highlight what truly matters in our testing efforts.
- Several extensions can help you with writing the property, for example, zod-fast-check, this library helps you generate the arbitraries from zod validators.
Drawbacks
- Property tests might take longer to write because, as we mentioned earlier, we are defining or creating how the magic oven should work. So, writing a meaningful and comprehensive property that captures the requirements can be harder but probably more rewarding.
- As the assertions are run with several inputs, the test may be slower and more resource-intensive.
- The learning curve can be higher, but I really like the fast-check learning path and tutorials. It makes it really simple to get started. Probably, when combining it with UI test tools like Cypress, it can become a bit more difficult.
Summary:
Property-based testing can be a valuable addition to your testing toolbox. I think finding and truly understanding the purpose of the function you want to test can help you construct the property. As described in the example above, recently, I was working on a deserialization task for a rich text editor that converted legacy schemas to new ones. I needed to test if many cases were going to be ok when the deserialization happened, so thinking of schemas with headers, bolds, images, lists, etc was hard so I ended up writing an arbitrary that created many inputs. It helped a lot to have more confidence in that code.
I don’t think it replaces example-based tests or common testing, but it can be used to complement them. Having a power that can check more edge cases for you is really valuable, but it also comes with the responsibilities and challenges of learning, thinking, and understanding the main purpose of your function and the value that you want to get from testing it.
References:
- https://fast-check.dev/
- https://fast-check.dev/docs/introduction/why-property-based/
- https://fast-check.dev/docs/tutorials/quick-start/
- https://jrsinclair.com/articles/2021/how-to-get-started-with-property-based-testing-in-javascript-with-fast-check/
- https://jsverify.github.io/
- https://medium.com/criteo-engineering/introduction-to-property-based-testing-f5236229d237