





In part 1, we explored the origin of natural language processing systems and their evolution from a set of hand-crafted rules to data-driven approaches. We then explored the appearance of word embeddings, a groundbreaking method for representing words while encoding their semantic meaning. We are now ready to understand the key elements that led to LLMs, how they work, and what might come after the current era of LLMs.
Understanding sentences, not just words
With the advent of word embeddings, machines could understand words better than ever before; however, there were still significant weaknesses that limited their performance on real-world problems. One of the main weaknesses is that word embeddings assign a single vector to a word, but in day-to-day language, we may have words that can mean totally different things based on their context. For example, the word bank will have a totally different meaning in the following two sentences:
- They sat on the river bank and watched the sunrise
- They deposited the check at the bank before leaving for dinner.
With previous word encoding approaches, "bank" would be represented in exactly the same way in both sentences. There was a need to be able to inform models in some way that the “bank” from the first sentence conveyed a different meaning than the “bank” from the second one.
To solve this, researchers began building models that could read text more like we do: one word at a time, considering what came before each word. These models are called sequence models, since they process words as part of a sequence rather than in isolation.
One of the first sequence models was called Recurrent Neural Network (RNN). If we go back to our previous explanation of neural networks, the idea was simple: we send them a vector (text representation), the neural network performs some operations on the vector, and we get another vector as output. Once the output is produced, the neural network starts fresh again for the next input. What recurrent neural networks do is to add some form of memory to the neural network. They do this by carrying the output from each step (after processing the word) as an input to the next step, along with the next word. You can visually think of an RNN as many neural networks stacked up in a row (one for each word in our input text), where the output of each neural network is fed as an input to the next neural network.
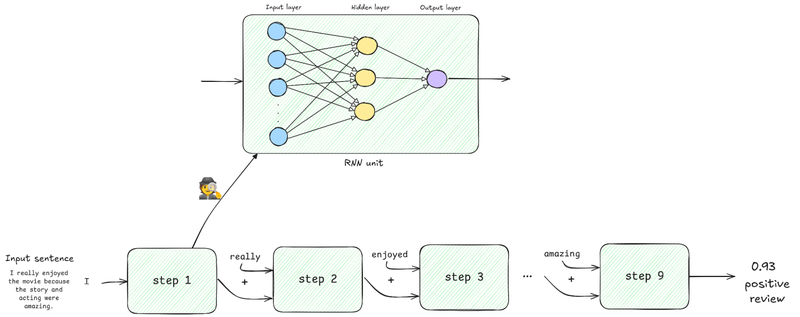
While RNNs were a big step forward, they had a serious flaw: their memory wasn’t very reliable. They could handle short sentences very well, but as the text was longer, they tended to forget information from earlier on. Suppose you go back to the previous diagram as the stack of neural networks gets larger. In that case, the input that we sent to the second neural network gets diluted due to all the operations that were done in the following neural networks. This is known as the vanishing gradients problem. Researchers found a way to mitigate this problem with more advanced approaches like Long Short Term Memory (LSTM) networks.
Thanks to their ability to remember words in order and retain important context over time, RNNs and LSTMs brought significant improvements to NLP tasks like text generation, machine translation, and speech recognition. However, there were still a couple of pain points that hindered their performance for many tasks. First of all, although the vanishing gradients problem was alleviated with LSTMs, it was still an issue with long texts. This, combined with their architecture, made them quite tricky to train without leading to overfitting. The second issue was that these systems were slow to train and required a lot of computational resources.
To overcome these challenges, researchers began exploring new architectures. The most successful of these was the Transformer, introduced in 2017 by Ashish Vaswani and colleagues at Google Brain. Transformers would go on to become the foundation of large language models, and are widely considered the missing piece that made AI language understanding as we see it today possible.
The main building block of Transformers is known as the attention mechanism, and its idea is quite simple: could NLP models process entire documents at a time, while just focusing on the most important words? Consider a sentence like the following as an example:
“The cat chased the mouse, but after a while, it got tired and stopped.”
Instead of treating all words equally, attention allows a model to focus more on the words that are most important for understanding a given part of a sentence. For example, if the model is trying to interpret “it” in the sentence, it will pay more attention to “cat” than to less relevant words like “while” or “but.” This helps the model build meaning based on context, not just word order.
Transformers took the attention idea and built an entire model around it. Unlike sequential models (like RNNs and LSTMs), which read text one word at a time, Transformers read all the words at once. This means that they can make connections between words, no matter how separated they are. With the arrival of Transformers, we could now capture longer dependencies in text and scale models more efficiently, thanks to much faster processing. We now had all the necessary ingredients in place to start building large language models.
Large Language Models are born
So, now that we have reached this point, we can actually answer the following question: What defines a large language model? LLMs are basically transformer models with billions of parameters, trained on huge amounts of data. For example, GPT-3 was trained on a dataset consisting of ~400B tokens (570GB of text). If we compare this to the number of words in an average novel (~130,000 words), GPT-3 was trained on a dataset with the size of 3.1 million books. This data is obtained from a mix of sources from the web, both filtered and unprocessed, such as Wikipedia, academic articles, code repositories, and books, among others. Working with such volumes of data was inconceivable before, but advancements to GPUs and the introduction of transformers made this possible.
The next question to answer would be how LLMs are actually trained. There are two main ways of training a model based on the amount of manual intervention that is required: supervised and unsupervised approaches. The former requires labelling the data that we are feeding to the model, while the latter just relies on the data itself to train the model. Since labelling such an enormous dataset is not feasible, LLMs are trained using an unsupervised approach. This approach varies by the final LLM architecture. One example consists of taking sentences from the training dataset, masking some tokens, and using the model to predict what the correct values for those masked tokens are. Since we know what the correct value would be, the model will know when its prediction was correct or not, and learn from that.
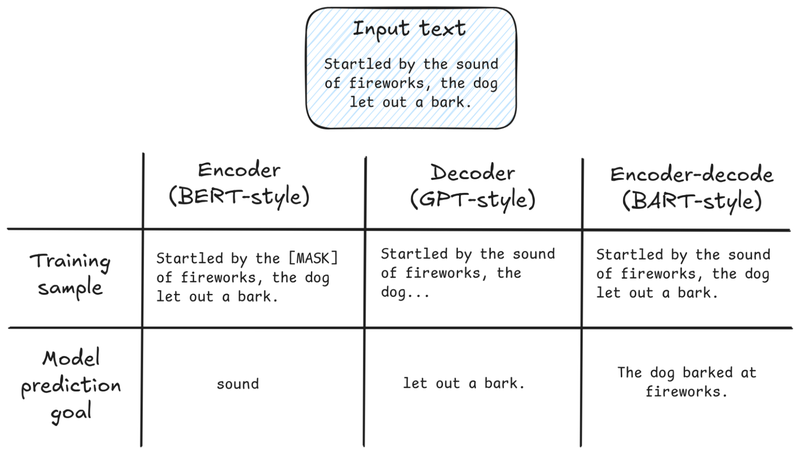
By learning to predict the next token, the model learns not just grammar and vocabulary, but also facts about the world, styles of writing, and even some basic reasoning patterns.
Once a model is trained in this way, it becomes a general-purpose language model, capable of generating text. However, while it can generate anything, it still does not understand which content can be helpful, truthful, or harmless. That's where the next phase comes in: fine-tuning. Fine-tuning is a term common to any machine learning model. It refers to the process of taking an already trained model, leveraging the knowledge it already has, and training it further with a specific dataset. This is usually done to improve the model with a specific goal in mind.
There are two main fine-tuning steps common to most LLMs. The first one consists of training the model with a set of curated instruction-response pairs. These pairs may contain examples of how a human might request something from the model and how the model should respond to that.
The second fine-tuning step can actually be seen in most LLMs with user interfaces, and it is called Reinforcement Learning from Human Feedback (RLHF). This basically consists of leveraging feedback given by humans who are using the model to improve future responses given by the model. This is usually done by making user rate answers (e.g. thumbs down/thumbs up) or by giving multiple responses to the user and making them select the best response.
Now that we know how these models are trained and fine-tuned, we can better understand why they are so powerful. Since they were trained on such massive volumes of texts, they can recognize patterns in language and answer in ways that feel surprisingly natural. As you may already know, this makes them extremely good at producing vast amounts of information related to widely different topics.
However, when the user request goes beyond the scope of knowledge available in the dataset, that’s when we can start noticing their weaknesses. LLMs are not so great at reasoning or deriving new knowledge, leading to hallucinations. Related to this is their subpar performance with mathematical calculations. If you think about it, LLMs work by predicting the most likely sequence of words based on context, not by performing step-by-step arithmetic.
There are additional concerns related to biases and security that need to be considered. Since LLMs are basically summarizing and transforming information available in the training dataset, they can sometimes reflect or even amplify existing biases found in that data. This can lead to unfair or misleading outcomes. On the security side, these models may unintentionally leak sensitive information or be manipulated to produce harmful content. Although most of these security issues are common to all NLP models, they have become even more prevalent with the increasing adoption of LLMs.
Before we wrap up this section, it’s important to note that confidence does not equal correctness, especially when it comes to LLMs. As we have seen previously, LLMs are fine-tuned through RLHF to optimize for signals of user satisfaction, not truth. Many of you may have probably noticed this already: it’s common for an LLM to respond with great certainty, only for the answer to have significant flaws. Additionally, LLMs will often reinforce a user’s idea, even when it’s not the best decision. Therefore, it’s crucial to make responsible use of these technologies. They can be extremely useful to speed up daily tasks, but their output should always be double-checked, especially if it involves making important decisions.
The future of NLP
Due to the great capabilities of LLMs for many different practical applications, it’s fair to say that they are the most transformative leap NLP has ever experienced. We are currently riding a wave of hype where users are finding out potential use cases for LLMs: from individuals planning out their next workout routine to businesses triaging potential candidates based on their CVs.
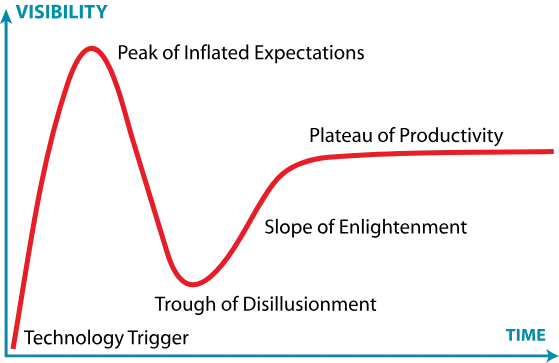
Researchers are continuously feeding more data and building ever larger models in an effort to create systems with improved pattern recognition, emergent abilities, and even more coherent text generation. However, as many researchers such as Yann Lecun have already pointed out, scaling alone will not be enough to achieve true reasoning or intelligence without additional architectural breakthroughs. If you are familiar with the Gartner hype cycle, everything seems to point out as if we are close to reaching the peak of inflated expectations (or perhaps we may already be there).
It’s crucial to avoid the hammer problem during these times of inflated expectations, especially from a business or consultancy point of view. The current trend is to forcefully fit LLMs into every possible NLP task, but we need to remember their strengths and weaknesses.
Whenever we face a domain-specific task where hallucinations are particularly dangerous, smaller supervised models should be considered. An example of this would be a medical assistant trained on clinical records, where precision and factual correctness are critical. We should also consider smaller models in cases where the task at hand doesn’t require the massive computational power and pattern-matching capabilities of LLMs, and simpler models would perform comparably or even better.
When we inevitably reach the trough of disillusionment (or even a new AI winter), it will also be important to remember the genuine capabilities of LLMs. Their great pattern matching, summarization, and text generation capabilities allow us to speed up many tasks in our daily life. Rather than fading away, LLMs will most likely settle into a more mature role as part of the standard NLP toolkit.
So, the final question in our NLP journey would now be: what’s coming next? As we have mentioned earlier, if we want to move forward in the pursuit of Artificial General Intelligence (AGI), some architectural and methodological breakthroughs will most likely be necessary.
One focal point is integrating verification mechanisms to make sure that information returned by the LLM is formally accurate. A line of research is developing methods to automatically curate the datasets used to train these models: the cleaner and more representative the data, the less likely a model is to give inaccurate or biased results. Other directions focus on complementing LLMs with other tools from the NLP ecosystem. If you remember our first chapter, we briefly discussed ontologies and how they allow us to formally define concepts about the world and their relationships. There is ongoing work in exploring how ontologies (and similar structured knowledge representations) can be used to improve the factual accuracy and reasoning capabilities of LLM responses.
If we circle back to our opening thoughts, much has changed since Alan Turing first introduced the concept of AI. Recent progress with LLMs has taken us to levels that were unimaginable ten years ago. As Dan Klein, professor of computer science at UC Berkeley, explains in his talk “Are LLMs the beginning or the end of NLP?”, we are most likely still only at the end of the beginning of NLP. These models have allowed us to encode vast amounts of text into internal representations that machines can efficiently understand and manipulate, but we still have many unsolved problems and a long journey ahead.
This journey is exciting for some and daunting for others. We are trying to build systems that truly reason about and understand the full complexity of our world. Systems that not only process information but also connect with human emotions in meaningful ways. Systems with the potential of surpassing human knowledge, making advancements in fields like mathematics and physics. While this is just the end of the beginning, now more than ever we must remain mindful of the challenges and risks (ethical, social, and technical) that come with creating AIs powerful enough to shape and dictate our future.
Additional resources
For readers who want to further explore these topics, I recommend the following resources: