






You've probably heard of "types" and maybe even "type systems" in your learning so far as a #c0d3r. For example, you've possibly heard that Ruby is strongly typed, while C is weakly typed (though these definitions are actively debated). Type systems are quite helpful - to varying degrees, they ensure the integrity and expected behavior of our programs. But more generally, types provide us a formal system for posing questions of logic & determining whether that question is, in fact, answerable.
But where did these super-powered "types" come from? As it turns out, the type systems that we use every day in our programming languages are descendants of a field of logic known as type theory. In the next 10 minutes (I promise!), we'll discuss the origins of type theory, the typed lambda calculus, as well as functional programming languages while connecting the dots along the way.
Special thanks to Tom Ellis and Adam Chlipala for their review and corrections of an early draft of this post.
Leibniz Sets The Stage

Leibniz - who demonstrated the superiority of the binary over the decimal representation for mechanical computers back in, oh, 1680 (!) or so - was such a proponent of algorithmic solutions to all problems that he would recommend to disputants in any field to sit down at a table, take out their pens, and say:
"Calculemus!" (Or: "Let us calculate!")
Leibniz therefore had as an ideal the following:
- Create a "universal language" in which all possible problems can be stated.
- Find a decision method to solve all the problems stated in the universal language.
Henceforth I will refer to Leibniz's "ideal" as the challenge to define "effective calculability." Many would rise to Leibniz's challenge - to implement such a system to formally pose & solve all problems - including one Bertrand Russell.
Russell Rises to Leibniz's Challenge

One of the better-known mathematician-logicians to grapple with Leibniz's effectively-calculable challenge was Bertrand Russell. His opus Principia Mathematica represented an early attempt to create a logical basis for all of mathematics - that is, an attempt to define effective calculability for all mathematical problems. Russell's theory of types was introduced as a response to a logical contradiction in set theory that resulted from Georg Cantor's theorem that no mapping of a function F across a set X to its "powerset" P(X) (where P(X) is the "set of all subsets" of the set X)
F : X → P(X)
can be surjective (i.e. F cannot be such that for every b in P(X), there is a value a in X such that F(a) is equal to b). This can be phrased "intuitively" as the fact that there are more subsets of X than elements of X. (Or perhaps even more intuitively: there cannot be a 1:1 mapping between any set X and its "powerset" P(X), because there exist more subsets of X than distinct elements of X.)
A Quick Example of Cantor's Theorem
Let us take, for example, a set of primitives X -> {1, 2, 3}. The cardinality (i.e. the number of elements contained in the set) of X is 3. What is the cardinality of the powerset P of X? Well, with the powerset defined as "the set of all subsets," let's enumerate P(X):
P(X) = { ∅, { 1, 2, 3 },
{ 1 }, { 2, 3 },
{ 2 }, { 1, 3 },
{ 3 }, { 1, 2 } }
As you can see, the cardinality of P(X) is 8 since there are 8 subsets in total. More generally, the relationship between X and P(X) is represented by the function f(x) = 2^x. In other words, a set X with cardinality n will have a "powerset" P(X) whose cardinality will be equal to 2^n. Cantor's theorem extended this logic to infinitely-large sets as well.
Here's a visualization of the concept of powersets, over an abstract set X -> { x, y, z }:
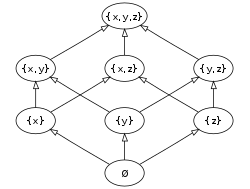
Demystifying Russell's Paradox
For Russell, Cantor's Theorem was problematic towards his efforts to define effective calculability. After all, how can one produce a decision method to solve a problem concerning an infinitely-large powerset that is even more infinitely-large than, say, the infinitely-large set of real numbers? (Whew!)
As Russell grappled with Cantor's Theorem, he observed a rather confounding feature of naïve sets. In attempting to map the set of all sets "which are not members of themselves," a paradox emerged.
To explain the paradox, let's start with another simple example. Using set-builder notation, we can express the set of integers greater than 3 and less than 7 as follows:
let x = { n: n is an integer and 3 < n < 7 }
Seemingly, we could provide any "predicate" (i.e. the logic that determines the set's members, or is an integer and 3 < n < 7 above) or proposition to describe the x that will comprise our set. One specific predicate leads us succinctly to Russell's paradox:
let y = { x: x is not in x }
Translated as: "Let y be equal to the collection of sets x, where each x is not a member of itself." Another translation: "Any set - for example b - that is not in y must contain itself, since y is the set of all sets that do not contain themselves."
Is the set we've just defined y itself a member of, or "in," y? Either answer leads to a contradiction:
- If we concede that
yis in fact a member ofy, then we have violated the predicate logic thatyonly contains sets that do not contain themselves. - If we then declare that
yis NOT a member of (is not "in")y, then we are saying thatyis a set that contains itself. (Prepare for brain-melting.) Basically, sinceydoes not contain itself, it must be a member ofyas we have satisfied the predicate - but this contradicts our declaration upfront thatyis NOT iny.
Therein lies Russell's Paradox. (You can read here for further discussion if you're still a bit confused - which is to be expected, frankly.)
The Issue: Unrestricted Comprehension
In the language of naïve set theory, Russell's Paradox is a result of the axiom schema of comprehension (unrestricted), which states:
There exists a set B whose members are precisely those objects that satisfy the predicate φ.
As we've just seen, the above axiom leads directly to Russell's paradox by taking φ(x) to be ¬(x∈x) (i.e., the property that set x is not a member of itself).
Like many paradoxes, it certainly feels like Russell's Paradox stems from a certain ambiguity of terms. Does it make sense to talk about a set that contains itself? Can the set of integers {1,2,3} really contain itself - that is, contain the set {1,2,3} - as one of its sub-sets? The problem in the paradox is that we are confusing, in the example of the set {1,2,3}, a description of sets of integers with a description of sets of sets of integers. We are allowing a predicate to act on itself in asking whether set X contains X.
(NB: As we will see with the typed lambda calculus, this is akin to a proposition of the form P(P), which is not expressible in that system and hence we neatly avoid the paradox.)
Type Theory to the (Paradoxical) Rescue!
Type theory was born from the realization that sets constructed hierarchically could not suffer from the Paradox. In type theory, Russell introduced a hierarchy of objects: numbers (type 0), sets of numbers (type 1), sets of sets of numbers (type 2), and so on ad infinitum (type n).
The set of numbers {1,2,3} can now be expressed as having type 1 - it contains number objects of type 0. We now restrict our set {1,2,3} from including itself as a member since it can only include objects whose type is less than 1. As succinctly as the Paradox was expressed above, we have now banished it from existence by assigning a type to every possible set.
The Untyped Lambda Calculus

Alonzo Church first introduced the λ-calculus as "A set of postulates for the foundation of logic" in two papers of that title published in 1932 and 1933. Like Russell with his theory of types, Church had set out to formalize the concept of "effective computability" (which eventually developed into the concept of a computable function, or algorithm). In short, the lambda calculus is a formal mathematical system for expressing the notion of computation. The name derives from the Greek letter lambda (λ) used to denote binding a variable in a function.
Grammar Rules
The expression (later called a "term") λx.x2 corresponds to an anonymous definition of the mathematical function f(x) = x2.
The terms (formulas, expressions; these three are used interchangeably) of the calculus are defined inductively as follows:
xis a term for any variable.- If
M,Nare terms, then(MN)is a term. (This bullet corresponds to function application.) - If
xis a variable andMa term, then(λx.M)is a term. (This bullet is called "abstraction" and corresponds to function definition.)
Intuitively, the notation λx.M corresponds to the mathematical notation of an anonymous function x ↦ M (read: "variable x mapped to the formula M").
Booleans
Because everything is a function in lambda calculus, you may be wondering how basic logic is implemented at all. Let's take a quick look at booleans:
true = λxy.xfalse = λxy.y
In other words, true is a function of two arguments which returns its first argument and false is one which returns the second argument. (Further reading.)
Integers
Great, we have defined Boolean objects as functions, so we can check that box. But what about numbers? Those seem pretty important if we're going to implement a programming language in lambda calculus. As it turns out, Church developed a purely functional encoding for integers as well which are known as Church numerals.
All Church numerals are functions that take two parameters. Church numerals 0, 1, 2, 3, ..., are defined as follows in the lambda calculus:
0 = λab.b
1 = λab.ab
2 = λab.a(ab)
3 = λab.a(a(ab))
⁝
Perhaps this notation will look a bit more familiar (note that λfx simply binds f and x for use within the lambda expression; focus your attention on the number of times the function f is composed on itself to the right of the . in the expression):
0 = λfx.x
1 = λfx.f(x)
2 = λfx.f(f(x))
3 = λfx.f(f(f(x)))
⁝
In simpler terms, the "value" of the numeral is equivalent to the number of times the function encapsulates its argument. We have constructed a purely-functional implementation of natural numbers - how cool is that?!
We're almost there - we can finally see the building blocks for a programming language implemented with lambda calculus, but we're missing a crucial component: the relationship between mathematical proofs and computer programs carrying out instructions...
Unrestricted Comprehension Strikes Again! (The Kleene-Rosser Paradox)
As it turns out, the untyped lambda calculus suffers from a paradox of its own - one that strongly resembles Russell's Paradox. It's called the Kleene-Rosser paradox, and you can find an excellent discussion of it here at Brandon's blog. For our purposes, it's worth noting that the untyped lambda calculus - which originally represented another attempt to design a system of expressing the notion of computation - suffers from its own version of unrestricted comprehension that is very similar to that of naïve set theory in the absence of types which we discussed previously.
"Proofs as Programs": The Curry-Howard Correspondence
In the interest of time (read: I promised you ten minutes only!), I'll be succinct here. The Haskell wiki has a great explanation of the Curry-Howard-Lambek Correspondence, and in particular I found this example to be enlightening.
We can state the Curry–Howard correspondence in general terms as a correspondence between proof systems and type theories. One way of stating this is that types correspond to propositions, and values correspond to proofs.
Now, there are two kinds of propositions - theorems (which by definition have been proven) and non-theorems (which represent nonsensical, unproven propositions). When we write a function in Haskell, we're really posing a proposition and asking whether it can be proven (i.e. used as a theorem, or discarded as a non-theorem).
When interpreting a logical proposition as a theorem or nontheorem, you're interested in whether the type is inhabited (has more than zero values) or not. Therefore, the following program in Haskell (which I have borrowed from the excellent Haskell wiki pages) is, in fact, a proof:
theAnswer :: Integer
theAnswer = 42
In this not-so-exciting example, our proposition reads something like, "There exists something called an Integer", and our proof of this proposition is the value 42. Because the type Integer is inhabited (has values), we can consider our proposition a theorem (instead of a non-theorem). Let's look at a contrary example:
nonsense :: NonexistentType
nonsense = "foo"
Haskell will complain loudly at us when we try to compile this function. Why?
Proposition: There is such a thing as a
NonexistentType. Proof: The list of characters "foo"
Clearly, we've failed to demonstrate that the NonexistentType proposition is inhabited.
Let's take a look at a more interesting proposition-proof combination, a concat' function modeled after the Haskell Prelude library function of the same name:
concat' :: [[a]] -> [a]
Here we are given the type signature, which can be translated as follows:
Given a (polymorphic) list of lists containing values of type
a, a list of values of typeawill always be returned to us.
(NB: In Haskell, a String is equivalent to a list of Chars, which means a String type-checks with [a] in the type signature above.)
If we can demonstrate that a value exists for this proposition, then we have effectively proved the program to be logically consistent. Let's take a look at another example:
λ > concat' ["hello ", "world!"]
"hello world!"
By giving our computer the instructions to evaluate concat' ["hello ", "world!"] we have simultaneously proved the proposition that for some [[a]] we will be returned an [a]. We've bridged the gap between mathematical proofs and computer programs!
But there's something even cooler - since Haskell (and most functional programming languages at that) correspond to intuitionistic (or constructive) logic, we're also guaranteed to have an algorithm to arrive at our [a] return value from an [[a]]. And sure enough, here is that algorithm:
concat' [] = []
concat' (x:xs) = x ++ concat' xs
Because of the Curry-Howard Correspondence, our programs now represent mathematically-sound proofs (and vice versa). In other words, our programs (ahem) PROVE THEMSELVES at compile time.
Time's Up!
From Leibniz to Russell; from type theory to the lambda calculus; and from the simply-typed lambda calculus to Curry-Howard Correspondence, we've traversed the evolution of the idea of "effectively calculable" from the nonexistent ideal of philosophers & logicians all the way to self-proving functional programs (like the ones we wrote in Haskell). I hope you're inspired to dig a little deeper, and please let me know what you think in the comments below!
Acknowledgments
Once again, a special thanks to Adam Chlipala and Tom Ellis for their review and corrections of an early draft of this post. Tom Ellis is the founder of Purely Agile, a software development consultancy based in Cambridge, UK. Adam has written a book called "Certified Programming with Dependent Types". His research is primarily directed towards advancing the state of the art in automated program verification using proofs of program correctness - Leibniz would be proud!
Special thanks to Jakub Arnold (Stack Builders) for his early comments on a draft of this post.